March is end of fiscal year in most of Japanese company. I spent lots of time for paper work in these days… ;P
As many readers know that, DMTA cycle is key of drug discovery/optimization process and lots of computational and high thoughput experimental apporaches are available in the process recenlty.
I think AZ is the front runner of these area and I respect the activity because they do not only paper publication but also sharing the code. And by sharing the code, the code is improved by good open science community.
Today I read nice open access publication, published by Gian Marco et. al. from AstraZeneca(AZ). The title is “Augmenting DMTA using predictive AImodelling at AstraZeneca“. It’s worth to read because the author described the deitails of the infrastructure of Predictive Insight Platform(PIP) which is developed by AZ for improbing DMTA cycle with ML/AI.
Now almos 250 predictive models are working on the platform, tha task is not limited property prediction but also synthetic route prediction to evaluate proposed molecules. They provides ‘Global’ and ‘Local’ models for users, these models are optimized their developed QSAR engine named ‘Qputuna’. The origin of the name is that Optuna is used in model optimization step ;). I’m happy because optuna is developed PFN and the package is used world wide!
The service is used in small molecules but they are planning to expand the service for other modalities and planning to integrate LLM for support uses. I’m looking forward to future progress.
Interesting points for me are below.
– Cloud based #scallable
– Models are deployed as REST API #easy to integrate lots of services
– K8s is used for manage containers
By using these features PIP can keep high developability/fexibility. It seems really cool. Reader can read details without cost because this article is open access. So I would like to move coding. As I wrote above, Qputuna is used in the PIP and Qputuna is shared in AZ github repo. Let’s try to use it!
The structure of Qputuna is as same as Reinvent I think, config is defined by JSON file.
To build qputuna env, poetry is required, current my development environment is based on conda, so I developed the new envrionment for the task.
# install pyenv
# https://github.com/pyenv/pyenv?tab=readme-ov-file#installation
$ curl https://pyenv.run | bash
$ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bashrc
$ echo 'command -v pyenv >/dev/null || export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bashrc
$ echo 'eval "$(pyenv init -)"' >> ~/.bashrc
# qputuna is developed with python 3.10.10
$ pyenv install 3.10.10
# install poetry
# https://python-poetry.org/docs/#installing-with-the-official-installer
$ curl -sSL https://install.python-poetry.org | python3 -
Then I got qputuna from original repo and build the venv.
$ gh repo clone MolecularAI/Qptuna
$ cd Qptuna
$ pyenv local 3.10.10
$ petory env use 3.10.10
$ poetry install
After waiting the installation process, I could build the qptuna env ;)
Let’s run the command line for the test. Qputuna provides 4 commands, qputuna-optimize, qptuna-build, qptuna-predict and qptuna-schemagen. Last command seems generate JSON temolate for ML task, main command will be qptuna-optimize, build and predict.
Original document shows how to run the CLI with singularity container but I tried to run it from directly with same files today.
Here is the config JSON file.
The config defined molwt is target for the prediction and ECFP and MACCS keys are used for descriptors. I added “track_to_mlflow”:true for integrating mlflow with the experiment.
# examples/optimization/regression_drd2_50.json
{
"task": "optimization",
"data": {
"input_column": "canonical",
"response_column": "molwt",
"training_dataset_file": "tests/data/DRD2/subset-50/train.csv",
"test_dataset_file": "tests/data/DRD2/subset-50/test.csv"
},
"descriptors": [
{
"name": "ECFP",
"parameters": {
"radius": 3,
"nBits": 2048
}
},
{
"name": "MACCS_keys",
"parameters": {}
}
],
"settings": {
"mode": "regression",
"cross_validation": 3,
"direction": "maximize",
"n_startup_trials": 30,
"n_trials": 15,
"track_to_mlflow":true <<< ADDED
},
"algorithms": [
{
"name": "SVR",
"parameters": {
"C": {
"low": 1E-10,
"high": 100.0
},
"gamma": {
"low": 0.0001,
"high": 100.0
}
}
},
{
"name": "RandomForestRegressor",
"parameters": {
"max_depth": {
"low": 2,
"high": 32
},
"n_estimators": {
"low": 10,
"high": 250
},
"max_features": [
"auto"
]
}
},
{
"name": "Ridge",
"parameters": {
"alpha": {
"low": 0,
"high": 2
}
}
},
{
"name": "Lasso",
"parameters": {
"alpha": {
"low": 0,
"high": 2
}
}
},
{
"name": "PLSRegression",
"parameters": {
"n_components": {
"low": 2,
"high": 3
}
}
},
{
"name": "XGBRegressor",
"parameters": {
"max_depth": {
"low": 2,
"high": 32
},
"n_estimators": {
"low": 3,
"high": 100
},
"learning_rate": {
"low": 0.1,
"high": 0.1
}
}
}
]
}
To run the optimization, I type following command.
poetry run qptuna-optimize \
--config examples/optimization/regression_drd2_50.json \
--best-buildconfig-outpath qptuna-target/best.json \
--best-model-outpath qptuna-target/best.pkl \
--merged-model-outpath qptuna-target/merged.pkl
These structure is really similar to REINVENT ;) After few seconds I could get pkl and json in the my defined folder. Also I could get mlrun folder becuase I added option for mlflow.
Then run the prediction with the model.
poetry run qptuna-predict \
--model-file ./qptuna-target/merged.pkl \
--input-smiles-csv-file tests/data/DRD2/subset-50/test.csv \
--input-smiles-csv-column "canonical" \
--output-prediction-csv-file ./qptuna-target/prediction.csv
The command accepts smiles file as an input and generates prediction.csv with predicted value and smiles. It’s easy isn’t it.
Next let’s check ML flow.
$ poetry run mlfow ui
Then access localhost:5000. I could see all experiment results. To use the mlflow it is easy track ML process.
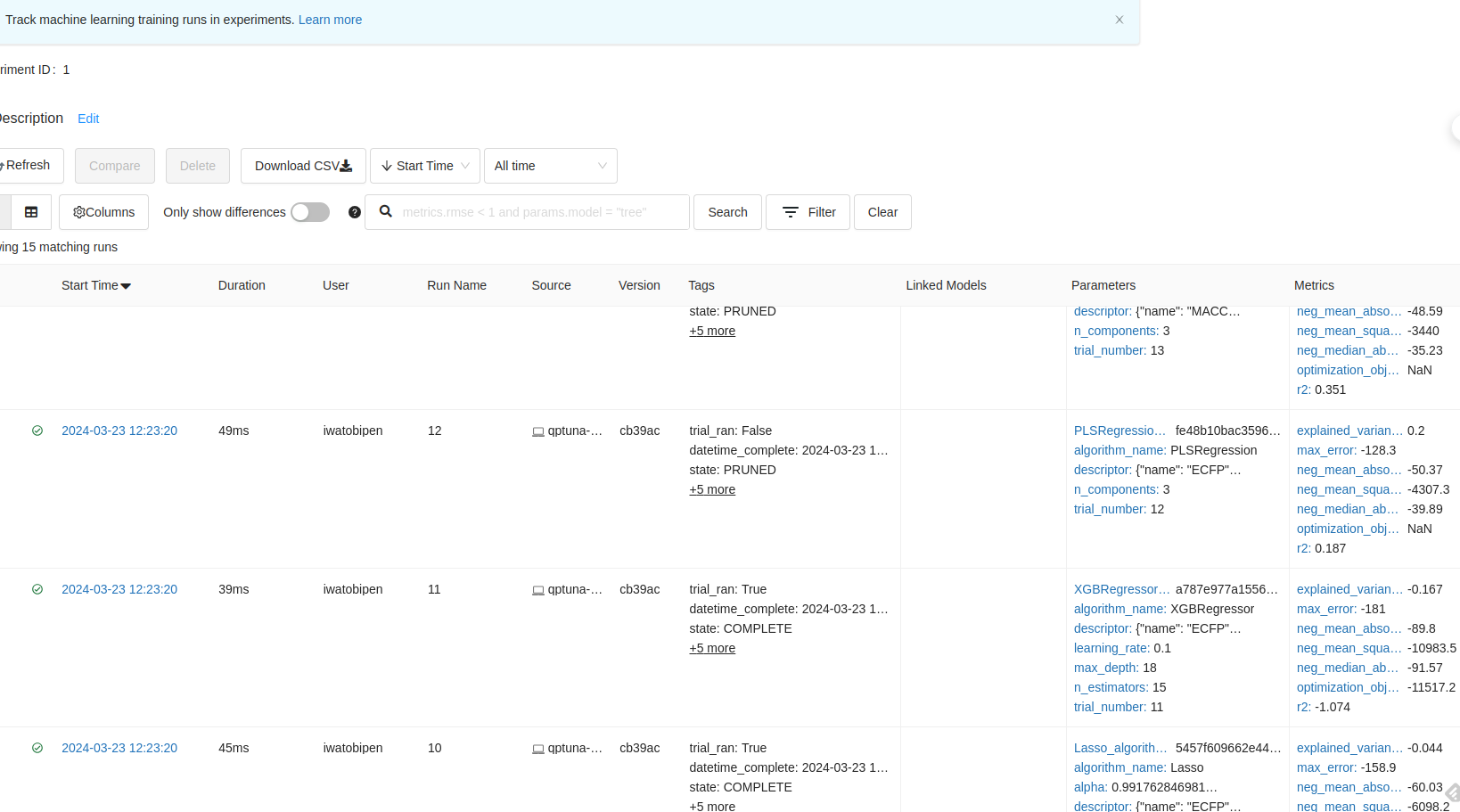
Also the repo provides lots of notebooks for using qptuna from python. Reader who has interest the package let’s try to use! Thanks for AZ team for sharing great code and article.
https://github.com/MolecularAI/Qptuna
I would like to also know that how they build the culture of prediction(AI/ML) driven research workflow with wet researchers. It’s too difficult task compared to build system.. IMHO
